
2021年10月20日 15:23 に「nik********さん」さんの以下の質問が目にとまったので、その答えを考えてみました。
質問の意味が分からない「Yahoo知恵袋」
助けてください。PDFの名簿をエクセル変換できる方法がありましたら 教えてください。グーグルドキュメントで試しましたら、1つのセルに全てのPDFが入ってしまって、途方に暮れています。 (重複している人もいるため、データをソート等したく、 名前・郵便番号・住所が別々のセルに入れたいのです・・・) 有料ソフトでも良いので、教えてください。
Yahoo! 知恵袋
この質問で分からないのは、「 1つのセルに全てのPDFが入ってしまって」の部分です。たぶん、この記述は誰も理解できないと思います。セルにはPDFは入りません!
PDFの文字認識がされているのであれば、Excelのデータ読み込みの問題になります。FDFが文字認識されていない(カーソルで文字を選択しようとしても認識しない)のであれば、OCRを用いて文字認識をする必要があります。
PDFからExcelにデータを貼り付けたい場合、いろいろなトラブルが発生することが想定されます。
発生するトラブルを解決するには、問題がPDF側にあるのか、Excel側で解消できる問題なのかを判断する必要があります。
この質問者さんは2分程度でこの質問文を書いたのでしょうが、この意味不明な質問に回答しようとする人にとって、回答する気力を無くさせるに十分な内容です。
質問の意味すら理解できないような書き方では、真面目に回答する気にもなれません。回答するには数十分かかるからです。
発生する問題として想定されるのは、以下のようなケースでしょう。
PDFデータを移行する際のトラブル
1. PDFから文字や数字をコピーできない
1.1 文字列だけでなく、PDF画面上で一切の選択ができない
1.2 選択しようとすると文字を認識しない
2. 文字のコピーはできるが、Excelにうまく貼り付けられない
2.1 PDFの表のデータがExcelの一つのセルに貼り付けられてしまう。
2.2 貼り付けたデータに空白や不要な文字が含まれる。
PDF側の問題解決
上の1.の問題は、PDFの問題です。1.1 はPDFのセキュリティ設定の問題で、1.2 は文字認識の問題です。
以降、操作手順は、無料で使える「PDF-XChange Editor」で説明します。理由は、OCR機能を使うケースも紹介するからです。
文字列だけでなく、画面上で一切の選択ができない
PDFの画面で文字列を選択しようとしても一切の選択ができない場合は、PDFのセキュリティ設定を最初に確認します。セキュリティ設定で、コピー禁止の設定がされていないかを確認します。
[ファイル] ⇒ [ドキュメントプロパティ] ⇒ [セキュリティ]
右側の[セキュリティ設定]が[セキュリティなし]、その下の「セキュリティ設定の詳細」が、「許可されています」になっていることを確認します。
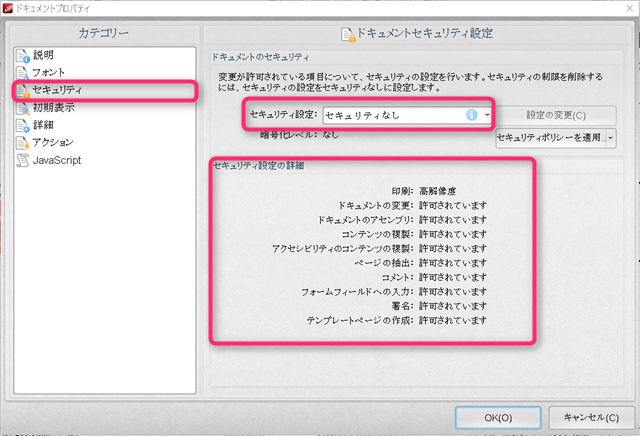
上のように表示される場合、制限はかかっていません。
制限がかかっていると以下のように表示されます。
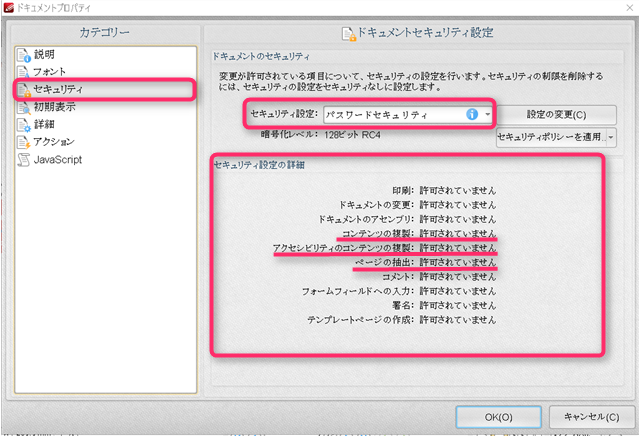
特に、赤線で引いた部分が「許可されていません」になっていると、PDFファイルから文字列や図などを抽出することはできません。
このような場合は、抽出を諦めましょう。
諦めきれない方は、セキュリティの解除という手段を執ります。たとえば、「PDF Password Remover」などのフリーソフトを使って、パスワード、制限を解除します。この手のソフトはたくさんありますが、配布しているサイトは怪しいサイトが多く、ウイルスをもらわないように注意する必要があります。どう注意したらよいか分からない人は、そもそも、この方法は諦めるべきです。
選択しようとすると文字を認識しない
PDF上で、文字列を選択しようとしても選択できない場合、そもそも文字列として認識されていない可能性があります。
このようなケースは、紙の原稿をスキャナーで読み込んでPDFとして保存した場合、あるいは、画像として読み込み、PDFで保存した場合です。両者はほぼ同じことです。後者では、たとえばカメラで撮影したjpgファイルをpdfに変換した場合などです。
このような場合、OCR機能を使って文字認識します。
セキュリティの制限がかかっていないことを確認した上で、次のように操作します。
メニューの [変換] ⇒ [ページをOCR]
日本語OCRはデフォルトではインストールされていないと思うので、[ヘルプ] ⇒ [ホームページ]でホームページを開き、検索で「OCR」と入力し、「Editor & Viewer OCR Language Files」をクリックして日本語韓国語OCR(OCRTessLangPack_JapanKorea.zip)をダウンロードします。
zipファイルを解凍すると、「OCRTessLangPack_JapanKorea.exe」という実行ファイルが一つだけ入ったフォルダが作られるので、この実行ファイルをクリック。インストールの初めに、日本語を選択。表示される手順に従いインストールを完了する。
これで、OCRで日本語が認識されるので、
メニューの [変換] ⇒ [ページをOCR] で文字認識を行う。
ただし、原稿の鮮明さが劣る場合、文字認識に失敗したり、誤認識・誤変換するケースもよく起こるので、チェックは入念にした方がよいでしょう。また、PDFが段組で構成されている場合、そのままコピーペするのは無理だと思います。
PDFデータのExcelへの貼り付け方
PDFからコピーしたデータをExcelに貼り付ける段階でさまざまなトラブルが発生します。
PDFの表のデータがExcelの一つのセルに貼り付けられてしまう
表をコピーしたのに、セルにうまく貼り付けることができないという問題です。特に、表形式の場合トラブルが起きる場合があります。以下、表の貼り付けの場合で説明します。 まず、PDFの表の文字・数値データをコピーして、Excelに貼り付けてみます。
その時、PDF上の表のように、Excelのセルに貼り付けることができれば問題ないのですが、多くの場合、失敗します。
たぶん、A列にすべてのデータが貼り付けられてしまうと思います。たとえば、PDF表の1行目にあるすべての値が、ExcelのセルA1 に入ってしまう。
このような場合、以下のように貼り付ける方法を変更します。
メニューの[データ] ⇒ [データツール]グループの [区切り位置]
これ以降の操作は文章では分かりにくいので、動画で説明します。
貼り付けたデータに空白や不要な文字が含まれる
PDFからExcelに表を貼り付けたい理由は、たくさんある数値の入力をコピーペで済ませたいから、ではないでしょうか。膨大な数の数値データを入力するのもチェックするのも大変な労力がかかります。
PDFからExcelのセルにうまく貼り付けたと思っても、不要な空白があると数値データとして認識されなかったりして何かと不便です。
こんな時は、余分な空白や文字列を一括して削除します。
これは、Excelのアドインで解決できると思います。たとえば、不要な空白や文字列を削除するには、「リボンの君と文字列変換」というアドインが便利です。


