はじめに
(はじめに、この記事はどんどん更新を繰り返しています。内容も高度化してきました。)
AIを使った画像の生成や動画の作成技術の進歩がめざましく凄いことになっている!
何が凄いかは、下のYouTubeをご覧下さい。
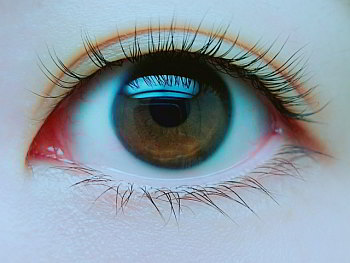
写っているのは管理人がAIに作らせた架空の少女です。さらに、その画像を使ってAIに動画作成させました。今回の記事では、その方法をざっくりとご紹介します。
(再生できない場合は、YouTubeでご覧下さい。)
AIの画像作成は、結構、難しそうです。関連サイトを見ても書かれている内容が高度すぎて意味不明。そこで、素人の管理人が、全くの初心者でもできるように説明したいと思います。
今回、web上でできる二つのAI画像生成ソフト(プログラム)を試してみました。どちらも、想像を超える品質に驚きっぱなし。こんなことができるようになったんだと、つくづく感じます。
でも、他人が作った作品を見ているだけでは物足りない。やはり自分が同じことをできないと単なる傍観者になってしまう。そこで、二つの無料ソフトの使い方を覚えることにしました。その結果が上のYouTubeです。綺麗に仕上がっていると思います。
今回の少女の画像は、AIが生成したものをそのまま使っています。通常であれば多少なりとも修正が必要になるのですが、その必要性を感じないほどのできばえに今回のAIソフトの優秀さを感じます。
AIを使って画像生成する「Stable Diffusion」と「Midjourney」
AIを使って画像生成するプログラムとして「Stable Diffusion」と「Midjourney」が有名なようです。ネット上で見かけるとても綺麗な画像もこれらのどちらかのプログラムを使って生成しているケースをよく目にするようになりました。
どちらも無料で使えるのですが、たくさんの機能があり、それ故、どう使ったら良いのか分かりません。
そこで、ターゲットを絞って使い方を覚えていくことにしましょう。
ターゲットとする画像
まずは、目標とする画像を決めます。
今回目標とするのは、下の画像です。

この画像は、最初、「オリジナルゲーム.com」さんの記事で見つけたものですが、今回、おなじものを作ってみました。
さらに、同じキャラクターの別バージョンについても作ってみます。

画像生成AI「Stable Diffusion」をノートパソコンで使う
上の画像は、「Stable Diffusion」を使って作っています。もっと詳しく書くと「Stable Diffusion web UI(AUTOMATIC111版)」のうち、テキストから画像を生成する「txt2img」です。
Stable Diffusion web UI(AUTOMATIC1111版)を使うには、NVIDIA製GPUが必要となりますが、管理人のノートパソコンには専用のGPUがないので使えません。そこで、Googleが提供するPythonを実装したウェブプラットフォーム「Google Colab」を使ってStable Diffusionをインストールすることで、NVIDIA製GPUなしの環境でも利用可能となります。
具体的な方法については、上で紹介した「オリジナルゲーム.com」さんのサイトに詳しく書かれているので、そちらを参照して下さい。
手順としては、Googleアカウントにログイン ⇒ 「Google Colab」を開く ⇒ 「Google Colab」に「Stable Diffusion」をインストール、という流れになります。
大体、5分程度、混んでいる場合は、10分から30分程度の時間がかかる場合があります。
上記の設定が終わり、Stable Diffusion の画面からの説明となります。
画面左上部の[Stable Diffusion checkpoint]の下が「Basil_mix_fixed.safetensors」となっています。読み込んだプログラム(モデル)が「Basil_mix_fixed.safetensors」だということです。別のプログラム(モデル)を読み込むことも可能です。これについては後で出て来ます。
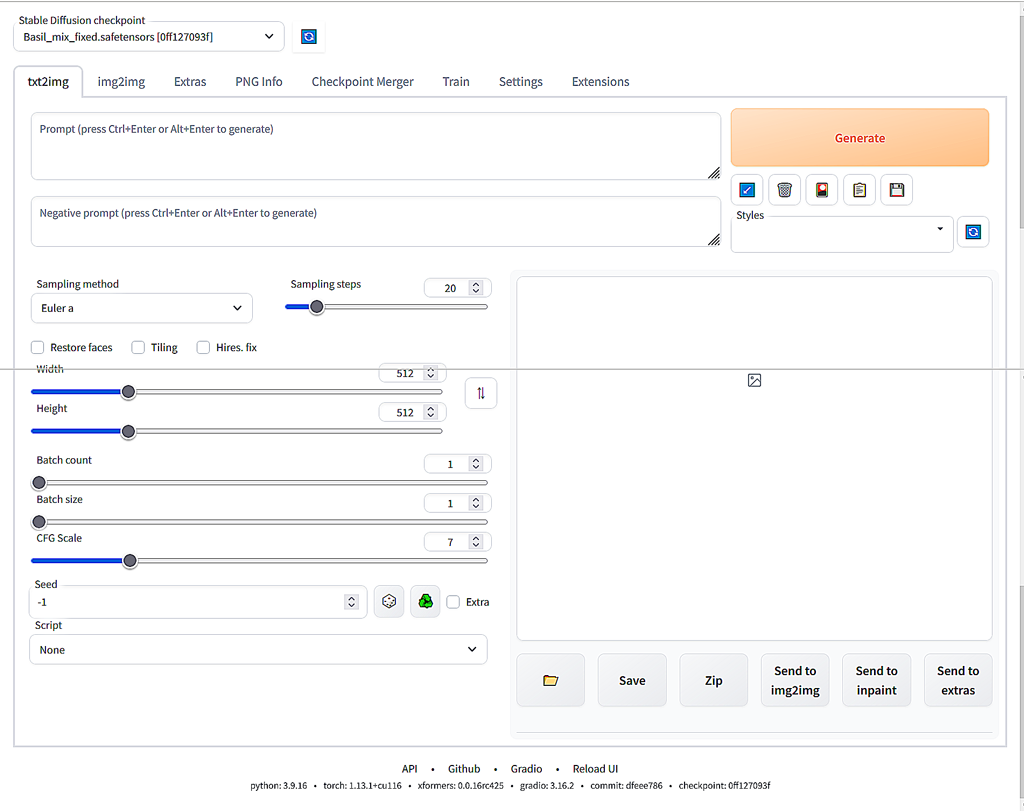
「Basil_mix_fixed.safetensors」を使う場合は、初期設定が必要です。
最初に、[Settings]タブを開き、①[Stable Diffusion] の② [SD VAE] を [Automatic] ⇒ [vae-ft-mse-840000-ema-pruned.safetensors] に変更します。
次に、③[Clip skip] を[1] ⇒ [2] に変更します。
最後に、④[Apply settings] をクリックして設定完了です。[txt2img] タブに戻ります。
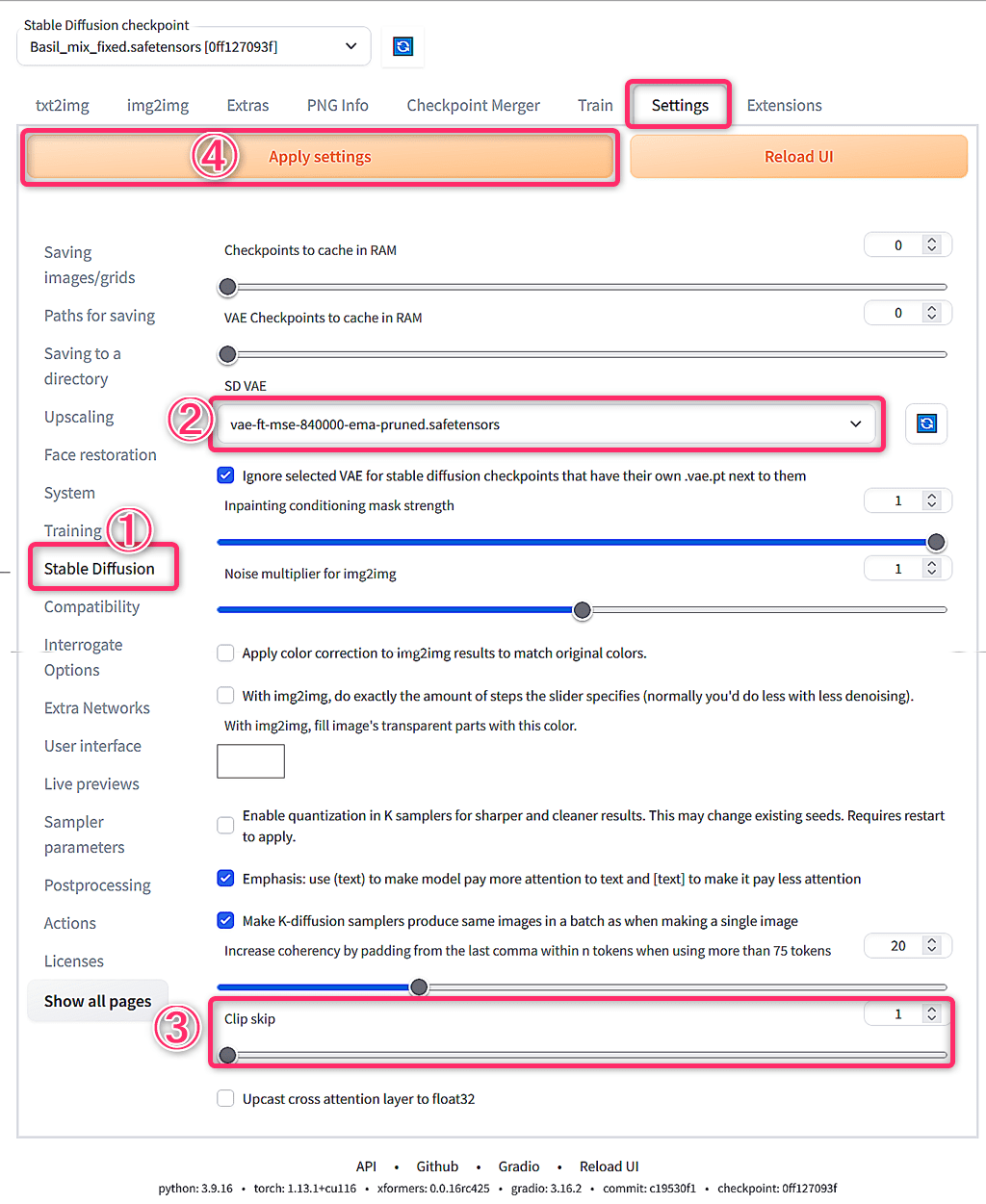
最初の [txt2img]タブに戻ります。
最初の空欄[Prompt]欄で、ここに、生成したい画像の特徴を英語で記載します。普通、英小文字で記載します。AIが大文字・小文字の違いを認識しない仕様になっているということで、大文字を使っても問題ないようです。
人物を生成したいのであれば、顔の向き、年齢、服装、背景、髪の色、顔の表情などの詳細を記入します。
今回の目的は、上で示した画像の再生成 なので、以下のように設定します。この設定が少しでも異なると全く別の画像が生成されます。このため、設定を完全に一致させます。
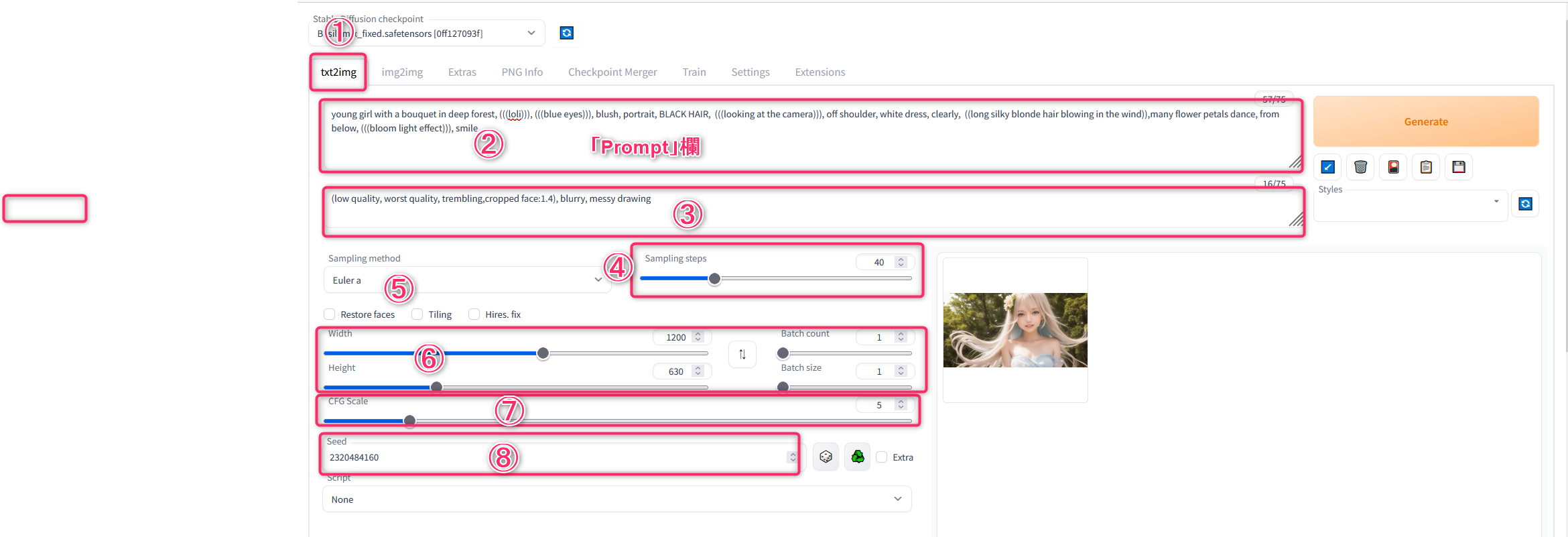
設定が終わったら、右上の[Generate] ボタンをクリック。生成が開始します。
ボタンをクリックしても数秒、何の反応も無いこともあります。
生成が終わると上の画像のようにサムネイルが表示されます。このサムネイルを右クリックして別ページで開くと、高画質画像を閲覧できます。気に入ったらダウンロードします。
以上のように、設定を完全に同じにすることで、同じ画像が生成されることがわかりました。
次のステップに進みます。
バリエーションを作る
気に入った画像が生成できたとき、そのバリエーションも欲しくなります。
[Prompt] の記述を一部変えることでバリエーションを生成できるのですが、全く別の画像が表示されるリスクがあります。
このため、操作する前に、[Seed] の横のサイコロの隣の緑色のアイコンをクリックして、Seedを再利用します。デフォルトの「-1」はランダム表示です。アイコンをクリックして少し待つと、現在表示している画像のSeedが表示されます。
上の事例では、Prompt の最後が [smile] になっていますが、これを [big laugh] に変更すると、以下のように生成されます。

バリエーションを作成する場合、最も簡単なのは、上図④[Sampling steps] の値を変更する方法かと思います。
上記の例では、[Sampling steps]の値は[40] になっています。この値の前後、5程度変更、つまり[35]~[45] 程度でバリエーションを生成できます。
Sampling steps: 42 にすると下のようになります。

バリエーションは、本来、seedの下にある [script] を使うらしいのですが、接続がタイムオーバーしたため操作の確認ができません。
[seed]の値は、2320484160を使っています。これを2320484362に変更すると下の画像のようになります。

また、⑦[CFG Scale]の値を変更することでもバリエーションを作成できます。上下▲▼のスピンボタンで、0.5刻みで変更できますが、それでは全く別の画像になる可能性があります。直接入力すると、0.1刻みで変更可能です。

他のタブを見る
今回使っているのは、[txt2img] というタブですが、その隣に [img2img] というタブがあります。これは、既存の画像と説明文を使って画像を生成することができます。ちょっと使ってみた限り、思ったような画像の生成はできませんでした。[txt2img]で使えるpromptの文字数は75文字までと制限があります。もっと詳細に指定したい場合、 [img2img] で画像を使ってイメージの概要をざっと説明し、promptで詳細を説明する方法が有効かも知れません。実際の所、ControlNetを使って生成したいポーズや構図を指定する方法が簡単です。
チュートリアルでは、 [img2img]でダビデ像を読み込み、Promptに、”make him a cyborg” と記述して、サイボーグっぽい画像を生成しています。こんな使い方も面白い。
[PNG Info] タブは、「Stable Diffusion」で生成し保存した画像の設定を確認できる機能です。生成・保存した画像をドロップすると、詳細な設定情報が表示されます。これを[img2img] や [img2img] に送ることができます。そのほかのタブは、よくわかりません。
Promptの書き方
Promptの書き方を簡単に説明します。
Prompt欄に生成したい画像の特徴を書いていくのですが、生成された画像を見て、期待したイメージと違うと感じる場合、何が違うのかを考えます。たとえば、blue eyes と書いたのに、青い目にならない場合など。そんなときは、言葉を強調します。
上の例では、[loli]という単語が三重括弧で囲まれ、(((loli))) となっています。()で囲むと、1.1倍言葉を強調できます。もっと強調したい場合、括弧を増やします。((loli))で1.1×1.1=1.21倍、(((loli)))で1.1×1.1×1.1=1.33倍になります。 しかし、これは古い表記方法で、現在は、(loli:1.1)のように、倍率を書くようになっています。この場合、1以上が強調、1未満は抑制となります。
その他、分からないことがあったら、githubのチュートリアルをご覧下さい。
追記します。
⑤の[Restore faces] のチェックは入れた方が良いようです。人物の顔の生成の崩れをかなり修正できます。
⑦の[CFG Scale] は、入力したPromptにどのくらい近い画像を生成するかのパラメータで、値が大きい程、Promptに入力した言葉に近い画像が表示されますが、見るに堪えない画像になります。0~20まで設定可能ですが、実際には、4~7くらいが良いと感じました。
では、CFG Scaleの値を20にすることはないのかというと、Seed固定とControlNetの画像指定の状態では、CFG Scaleの値を大きくした方が良い結果が得られる場合があります。
「Midjourney」を無料で使う方法
もう一つのAI画像生成プログラムMidjourney(ミッドジャーニー)も使ってみました。チャットサービス「Discord(ディスコード)」から使えます。
Discord経由の方法で無料で使えるのは約25枚までなので、あっという間に使えなくなりました。と言うわけで、使い方は書けません(www)。下の方で、Midjourneyを完全無料で使う方法を紹介しています。
Midjourneyの画質は申し分ないのですが、課金してまで使うというニーズがありません。
Discord経由の「Midjourney」の使い方はよそのサイトにお任せするとして、どのような画像が生成されるのか見てみましょう。

生成される画像は、たとえばサムライなどは国籍不明で、中国っぽい衣装、装具になります。見ていてあまり気持ちのいいものではありません。
画像はすばらしいのですが、あまり好きになれない。どうしても違和感を感じてしまいます。

二人の女性を生成したのですが、違和感を感じます。よく見ると髪型が変です。左の子は、ショートのおかっぱなのに、後ろの髪はどこから持ってきた?
右側の子は、あり得ない髪型です。前髪はどこに行ったのでしょうか。
AIはどのデータで学習したのでしょうか。少なくとも日本ではない。だから、違和感を覚える。違和感を覚える画像は使い物になりません。

Stable DiffusionでMidjorneyを動かす最も簡単な方法
ところで、上で紹介したStable Diffusion上でMidjourneyを動かす方法があります。やり方は最初に書いた方法と全く同じです。Google ColabのGPUを使うので、無料で使えます。
様々なサイトでやり方を紹介していますが、「camenduru」さんのページからアクセスする方法が最も簡単です。何しろ、ボタンを1個押すだけなので、これ以上簡単な方法はありません。
簡単に手順を書きます。
- Google アカウントにログインしておく。
- 「github.com」の「camenduru / stable-diffusion-webui-colab」にアクセス。
- 開いたページの最初の方に出てくる「README.md」をクリック。
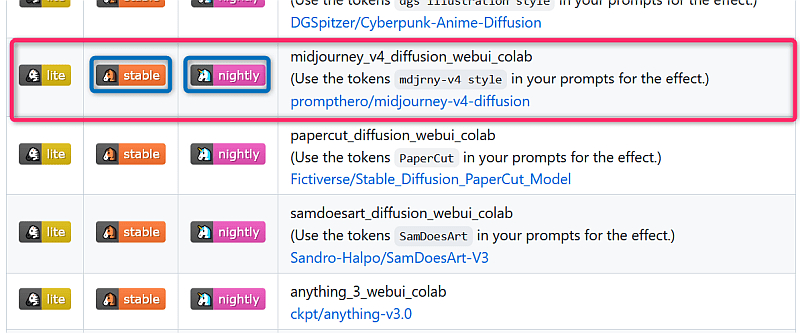
- 開いたページで、Midjourneyを探します。下のようになっています。
赤枠で囲んだ部分です。左側に[lite]、[stable]、[nightly]の三つのボタンがあります。違いは、読み込むスクリプトの数だと思います。一つのスクリプトのサイズはギガレベルなので、読み込みにとても時間がかかります。
Midjourneyをとにかく使ってみたい場合は、[lite] が軽くて良いでしょう。ControlNetを使う場合は、[stable]か[nightly]をクリックします(スクリプトをたくさん読み込みインストールするので時間がかかりますし、ドライブ容量を使います)。Googleドライブの無料枠は15GBまでなので、最初は[lite]がお勧めです。
なお、それ以外のモデルもたくさん用意されています。使い方は全て同じです。
5. ボタンをクリックすると、Google colabが開きます。その画面の上部バーにある「ドライブにコピー」をクリック。コピーが別タブに新規作成されます。作成が完了したら、このページは閉じてもOKです。
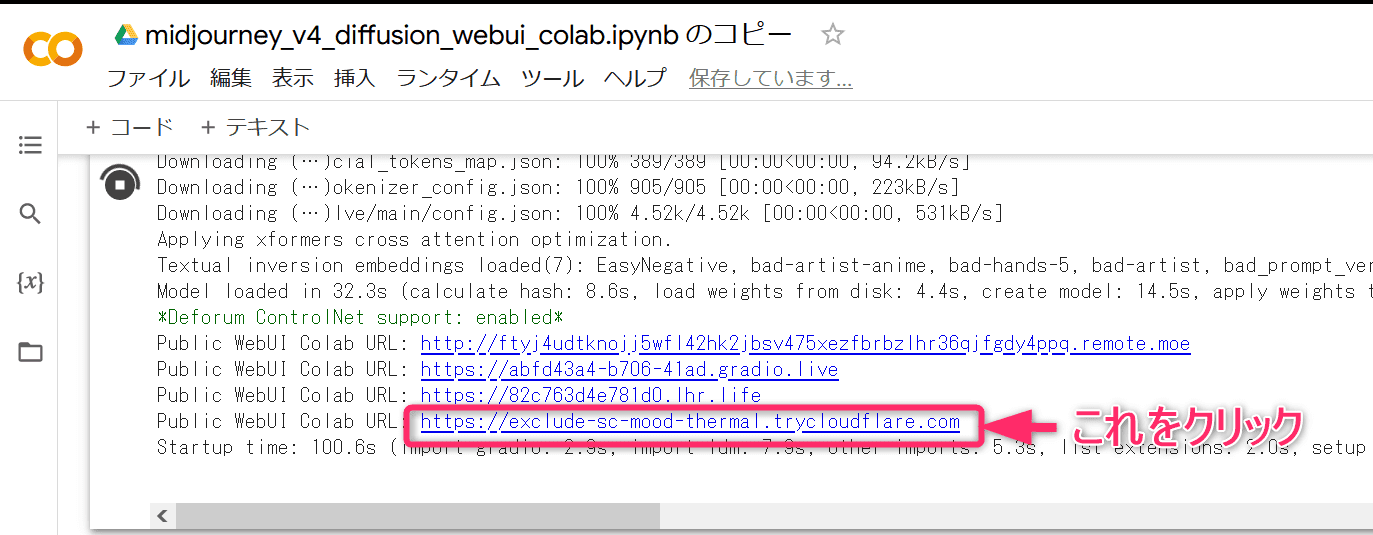
6. コピーされたGoogle colabのタブをみると、上部左側に黒地に白の横向き▲があります。これをクリック。▲が■に変わり、その周囲が回転し始めます。インストールが終わるまで6分から10分程度かかります(インストールといってもGoogle Drive上でのこと。PCにインストールするわけではありません)。
完了すると、[Public WebUI Colab URL:] の四つのリンクが表示されるので、その中の一番下のリンクをクリック。リンク先は毎回変わります(モデルによっては二つのリンクの場合もあり)。クリックするとStable Diffusionが開きます。これで、Stable Diffusion上で、Midjourney ver.4 が使えます。最新はver.5かも?
7. Google colabのタブとStable Diffusionのタブの二つが開いた状態で使います。

ここでは、Midjourneyについて書きましたが、他のモデルもなかなか面白い。上のようなメカニック系画像を生成するならモデルを「photorealistic_fuen_v1_webui_colab」か「f222_webui_colab」を選び、Stable Diffusiomの[Sampling method] を [Euler a] ⇒ [DDIM] か [UniPC] に変更すると良い結果が得られます。
画像から動画を生成する
YouTubeにアップした動画は、「HitPaw」というwebサービスで作成しています。無料で作成できます。
作り方は簡単で、画像をアップロードするだけです。問題となるのはダウンロード。無料でダウンロードするには、サイトの表示を無視し(www)、作成された動画をShift+右クリックしてダウンロードします。この方法を採ればロゴも表示されず、高画質の動画をダウンロートできます。
今回の動画では、Photoshopを使ってリバースを入れ、一部のコマ画像を修正しています。「HitPaw」で作成した動画では、女の子が口を開きっぱなしでアホみたいなので、口を閉じるコマを挿入しています。めんどくさいので適当に作ったのですが、もっと丁寧に作れば良かったと後悔しています。
さらに、リバース部分の速度を調整しています。
リバースを入れるメリットは、再生時間が2倍に増えること。あまり短い動画だとあっという間に終わってしまいます。「HitPaw」で生成される動画は12秒です。リバースを入れることで24秒の動画になります。リバース部分を継ぎ足して3倍、4倍の長さにすることもできます。その場合は、リバース部分の再生速度を変えたり、コマを追加・削除して、単なる繰り返し映像にならないように調整します。
二枚の画像から動画を生成する(モーフ)
Stable Diffusionで生成した画像が綺麗にできたので、動かしてみました。生成した二枚の画像のモーフです。単純な動画は退屈なので、ちょっと複雑な動きの動画にしました。
モーフ作業はこんな感じ。手間をかけずに20分で作りました。
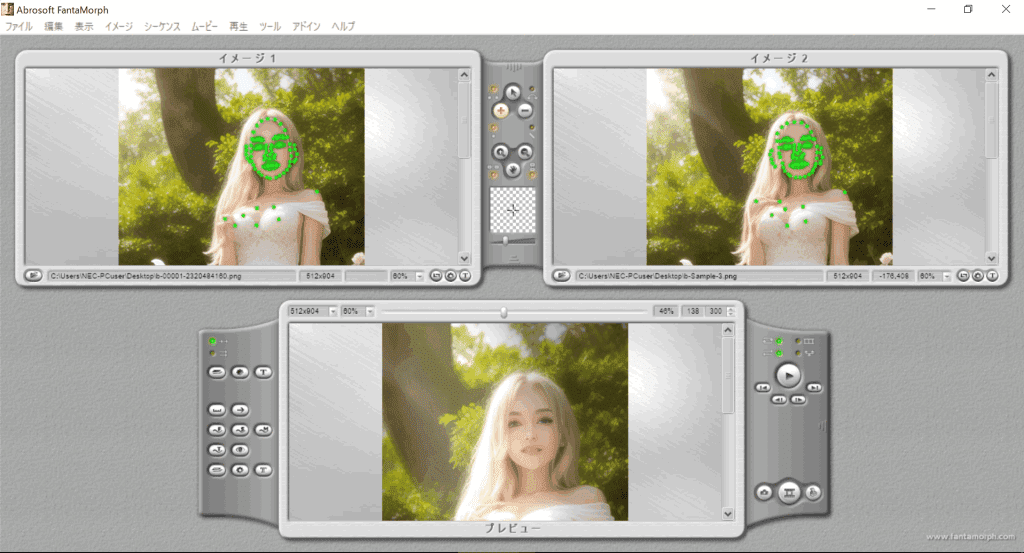
特徴カーブ、形状カーブ、トラックカーブ、カメラの設定をしています。単調そうに見えて複雑な動きをしています。

生成したお気に入り画像の設定パラメータの確認とその保全
この項目は、別記事に書きました。ControlNetを使ったモデルのポーズなども書いています。
『Stable Diffusionで生成した画像に埋め込まれているprompt等設定パラメータを確認する方法』
Stable Diffusionのトラブル解決策
Google ColabのGPUを無料で使っているため一部制限があります(実際には75文字以上入力するとこの上限が変わります)。
Google Colabの接続時間が長くなると接続が遮断します。そして、少なくともその日は同じアカウントでは接続できなくなります。そうなった場合は、別のGoogleアカウントを使えば接続できます。アカウントは複数作っておいた方が良いでしょう。これを毎日やっていると接続できないアカウントが増えるので、ネット接続には、VPN接続を使います。これで、一日中、毎日接続できます。アカウントがたくさん必要ですが。一つのアカウントで接続できる時間は2~5時間です。なぜ、こんなにばらつきがあるのか不明ですが、これが実態です。本格的にやりたい方は、有料プランに加入するという方法もあります。
Stable Diffusionが反応しなくなる場合があります。これには①Google Colabの接続が遮断している、②Stable Diffusionがフリーズしている、③正常に処理中(ただし、処理画面が表示されないだけ)、の3パターンがあります。
①の場合は、最初からやり直します。②場合は、ブラウザの再読み込み(リロード)ボタンでリロードします。ただし、作業中のPrompt等も消えます。③の場合は、Google Colabタブで進行状況を確認できます。10%、20%、30%と処理が進行していれば、そのまま待つだけです。
②の場合を補足すると、リロードした後、プロンプト欄などで読み込み中のマークが出る場合があります。それを待ってもたぶん無駄です。そんなときは、再度、リロードします。そして、プロンプトは保存したものを表示するボタンを使うのではなく、直接書き込んだ方が、エラーが出ず、時間の節約になります。動きが止まっていると感じたら、迷わずリロードしましょう。そのままStable Diffusionが表示されれば問題ありません。接続に不具合があれば、エラーが表示されます。
人物を生成するとき、あちこちに手足が生えたり、指が6本ある画像が生成することがあります。こんな時、まず、確認するのが、AIに実行できない矛盾する無効な指示を出していないのかという点です。特に、縦横比(デフォルトは512×512)の設定のまま、ポートレートを表示させようとおかしな指示をしていないか。逆に、極端に縦長画面にすると、いろいろなものが生えた奇妙な画像が生成されます。適切な縦横比を常に意識して作業した方が良いと思います。
この状況を少しでも改善できるのが、Prompt記入欄の下にあるネガティブプロント(Negative Prompt)です。一つの例として以下に紹介します。まずまず効くネガティブプロンプトだと思います。縦横比とネガティブプロンプトの組み合わせで、かなりの不具合を是正できます。
(bad prompt:1.61), (ugly:1.33), (duplicate:1.33), (morbid:1.33), (mutilated:1.33), (extra fingers:1.61), (poorly drawn hands:1.61), (poorly drawn face:1.33), (deformed:1.61), blurry, (bad anatomy:1.61), (bad proportions:1.61), (extra limbs:1.21), cloned face, (disfigured:1.61), (dead eyes:1.33), (out of frame), (6fingars:1.61)
おわりに
AIをつかった画像生成技術の進歩には目を見張るばかりです。
それを紹介する記事も見かけますが、他人の記事を紹介するだけで、使われている画像にオリジナルのものはありません。そんなサイトをよく目にします。
凄いと思ったことを記事にするのなら、自分でやってみるのが筋でしょう。自分でやってみて初めて分かることもあります。
今回の記事を書いたきっかけは、「オリジナルゲーム.com」さんのサイトで見かけた女の子の画像がとても気に入ったからです。この画像のバリエーションが欲しい。
そこで、AI画像生成について調べました。実は、過去記事『低解像画像の高解像画像への変換ができるAIを使ったPULSEとDeepMosaicsの比較』を書いているので、githubのプログラムの使い方は知っていました。このため、作業は何の支障もなく進みました。最近では珍しいことです。
管理人が知りたかったことは分かったので、記事はこれで終わりにします。自分である程度のことができるようになるという目的が達成されたからです。
今回苦労したのは、どのパラメータをいじれば目的の画像が生成されるのかということでした。分かった範囲で、それを書きました。

最後に、Midjourneyを提供しているDiscordについてです。このサービスは、必要以上に個人情報・パソコン情報を無断で収集しているようです。そのうち大問題になると思います。会社のパソコンなどからのアクセスは止めた方が良いと思います。