
今日は、ネットからダウンロードした数百ページ、数千ページの外国語文献を日本語で読む方法をご紹介します。
大まかな作業手順
ネット上で入手できる数百ページ、数千ページの外国語の書籍は、通常、PDF形式で配布されていると思います。歴史的な文献を無料で公開している公的機関が複数存在します。
これを日本語で読むためには、機械語翻訳サービスを使いますが、実際のところ、うまくいきません。それは、PDFの文書を機械翻訳するのが簡単ではないからです。
最初につまづくのが、PDFの文書が文字認識できない場合です。この場合は、OCR処理して、文字として認識させます。
次につまずくのが、抽出した文字列の1行毎に改行マーク(編集記号)が入っていること。このため、文章が細切れの状態として認識されることから翻訳エンジンが正しく翻訳することができません。この改行マークを取り除く必要があります。数百ページの改行マークをどうやって削除するのかが問題となります。
最後に、機械翻訳の能力です。数百ページもある文献を一括して翻訳するのは無料ではできません。また、翻訳エンジンの性能が最も重要となります。Google翻訳は使い物になりません。現在、唯一使えるのが「DeepL」という翻訳サービスです。5000字以上の翻訳は有料ですが、今回の目的のためには必須のものなので、契約する必要があります(実際には、1ヶ月間は字数無制限で無料で使えます)。
手順をまとめると、「PDFから正確に文字列を抽出する」 ⇒ 「抽出した文字列の改行マークを全て削除する」 ⇒ 「DeepLで一括して翻訳する」という作業の流れになります。
今回の作業では、対象となるPDFファイルのページ数がとても多いため、やり方を間違えると膨大な時間をロスします。そして、様々なトラブルが発生します。膨大な時間をロスする手戻りを繰り返した結果、管理人がたどり着いた方法をご紹介します。
早速、具体的にどのように作業をするのか見ていきましょう。
PDFファイルから文字列を抽出する
PDFファイルから文字列を抽出する場合、現在最も推奨される方法は、Googleドキュメントで文字を認識する方法です。有料のPDFエディタに付属しているOCRよりGoogleドキュメントの文字認識の方がはるかに高性能です。
PDFの文字列を選択できる、つまり、文字として認識されている場合であっても、実際には表示されている文字列とは別の文字として認識されている場合があります。性能の低いOCRを使い文字列の誤認識で苦労するより、最初からGoogleドキュメントを使った方が時間の節約になります。
作業を始める前に、PDFファイルのセキュリティ設定がどうなっているのか確認をしておきましょう。
PDFのセキュリティ設定の確認
PDFを開くソフトは、「PDF-XChange Editor」で説明します。他のPDF閲覧ソフトをお使いの場合でも、同じように確認できるはずです。
- 「PDF-XChange Editor」に翻訳したいPDFファイルを読み込む。
- [ファイル] ⇒ [ドキュメントのプロパティ] ⇒ [セキュリティ]と進み、[セキュリティ設定の詳細]の各項目が[許可されています]となっていることを確認する。
- 特に、[ページの抽出]が許可されていない場合、文字列の抽出はできない。その場合は、別のソフトを使って、この制限を解除します。たとえば、「PDF Password Remover」などを使うと簡単に制限解除できます。しかし、正規な方法で入手した文献のPDFファイルにはこのような制限はかかっていないはずです。最近は、「視聴覚障害者用スクリーン読み上げデバイスのテキストアクセスを有効にする」ことが求められているため、公的機関がPDFファイルのダウンロードを許可している場合は、文字列抽出制限はないはずです。
- 文字列は選択できるのにコピーできない、あるいは文字列の選択ができないという制限のかかったファイルもあります。このような制限は、Googleドキュメント上では無視されるので、PDFファイルの制限解除をしなくても作業上の問題はありません。ただし、ファイルを開くのにパスワードが必要な設定の場合はGoogleドキュメントではファイルを開けません。
PDFファイルの文字認識
PDFファイルを開き、[テキスト選択]で文字列を認識できれば、OCRを使う必要はない、と考えがちです。ところが、実は、これが単純ではないのです。文字列を選択できたとしても、それが本当に正しく文字として認識されているかどうかは別の問題です。コピーペすると別の文字列になることもあります。
ここで大きな手戻りが発生します。
また、「PDF-XChange Editor」には、OCR機能があります。これを使えばよいのではと考えますが、それではだめなのです。OCRの性能はGoogleが飛び抜けて優秀です。このため、「PDF-XChange Editor」のOCR機能は使いません。

この文字認識はとても重要です。手戻りにならないように、面倒でもGoogleドキュメントのOCR認識を使うべきです。(管理人はこれが原因で、数十時間の作業がすべて無駄になりました。)
Googleドキュメントは、PDFファイルだけではなく、画像ファイルからも文字を抽出できます。つまり、文字列の抽出に関しては、PDFファイルの文字が選択できるか否かは問題とはならず、抽出精度が優れているGoogleドキュメントにすべて依存するという方法が最も適しているのです。
Googleドキュメントによる文字列の抽出方法
Googleドライブの使い方
やり方はいくつかあるのですが、通常は、Googleドライブにファイルをアップロードし、それをGoogleドキュメントで開くという方法が一般的だと思います。その手順は以下の通りです。
- まず、Gmailにログインします。
- Gmailの画面右上にある四角い9つのドットのアイコン ⇒ [ドライブ] と進む。
- 「ドライブ」画面が開くので、左上の[新規] ⇒ [ファイルのアップロード] をクリック。
- 文字認識したいPDFファイルを選択し、[開く]ボタン。ドライブへのファイルの読み込みが完了したら、ファイルを右クリック ⇒ [アプリで開く] ⇒ [Googleドキュメント]
- [Googleドキュメント]が別タブに開きます。読み込みが完了すると、文字認識された結果が表示されます。
なお、画像ファイルの場合は、 [Googleドキュメント]の上部に画像ファイル、その下に抽出されたテキストが表示されます。
この方法のメリットは、 Googleドキュメント上でスペルチェックも文法チェックもできることです。 文字列の誤認識は頻繁に発生します。通常は、GoogleドキュメントでPDFファイルを開いた時点でスペルチェック結果が表示されています。読み取りミスや原稿の誤植もここで修正できます。
スペルチェックとハイフネーションの削除
さらに、メニューバーの [ツール] ⇒ [スペルと文法] を選ぶと、文法チェックできます。この作業が必要となるのは、PDFファイルの原稿の汚れなどで文字認識が不正確になる場合などですが、通常はスペルチェックだけで十分です。
行送りのため英単語の途中で入れる「ハイフネーション」の削除もこの段階で行います。自動で ハイフネーションが削除される場合もありますが、たいていは残ってしまいます。このハイフネーションが残っていると自動翻訳がうまくできません。
Googleドキュメントで文字認識に失敗する場合
Googleドキュメントでも文字認識に失敗し、まったく認識ではない場合があります。文字は問題なく読めるのになぜか文字認識できない、というケースです。たぶん、PDFファイルの埋め込みフォントが不正なのかも。
この場合、諦めるしかありません。諦めきれないときは、PDFファイルを一端、画像(TFFファイル)として出力し、それを再びpdfに変換するというプロセスを踏むと認識してくれる場合があります。PDF-XChange では[ファイル] ⇒ [エクスポート] 、画像として保存を選択します。
ページ数が数ページと少ない場合なら、PDFからページを抜き出し、それをpng形式に変換すると認識してくれます。”pdf to png” で検索すると変換サービスを提供しているサイトがヒットすると思います。
改行マーク(編集記号)の一括削除
次に、Googleドキュメントで抽出したテキストをコピーしてWordに貼り付けます。
Wordに貼り付けると、行毎に改行の編集記号が付いており、PDFの1行単位で改行された状態になっています。このままでは自動翻訳できないので、この「改行」マークを一括して削除します。

そこでまず、Wordの設定です。「改行」マークを表示させるように設定します。
Wordの設定
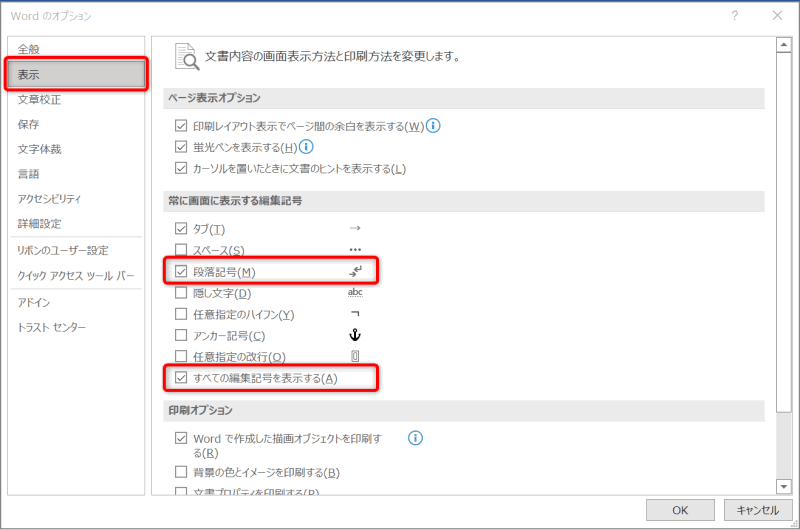
- Wordのメニューバー [ファイル] ⇒ [その他] ⇒ [オプション]。
- [Wordのオプション]画面が開くので、[表示] ⇒ [段落記号]にチェック。たぶん、[すべての編集記号を表示する]にチェックを入れたほうがよいかも。その場合、改ページやスペースの位置などが表示されます。
「改行マーク」の一括削除
改行マークを一括削除します。これは、Wordの置換ツールを使い、改行マークを空白に置き換えます。
- GoogleドキュメントからWordにテキストをコピーペする。
- Word上で、[Ctrl]+[A] で今貼り付けた文字列を選択
- Wordの[ホーム]タブの一番右側の [置換]
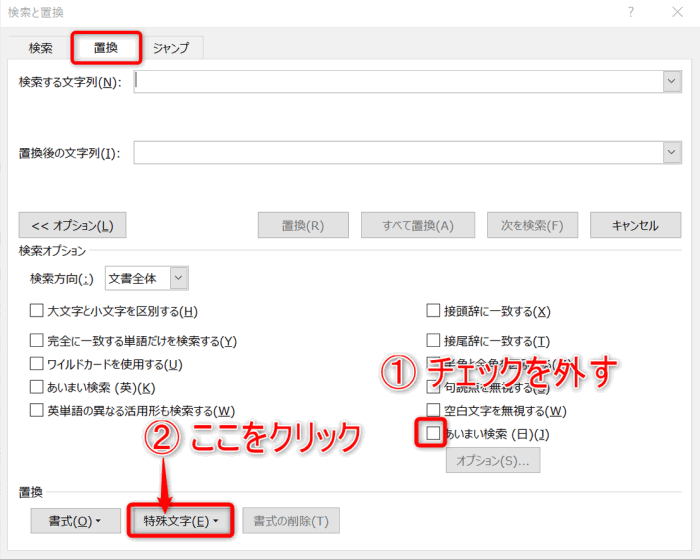
- 「検索と置換」ウインドウが開くので、[あいまい検索]のチェックを外し、[特殊文字]をクリック。開いたメニューの一番上の「段落記号」をクリック。
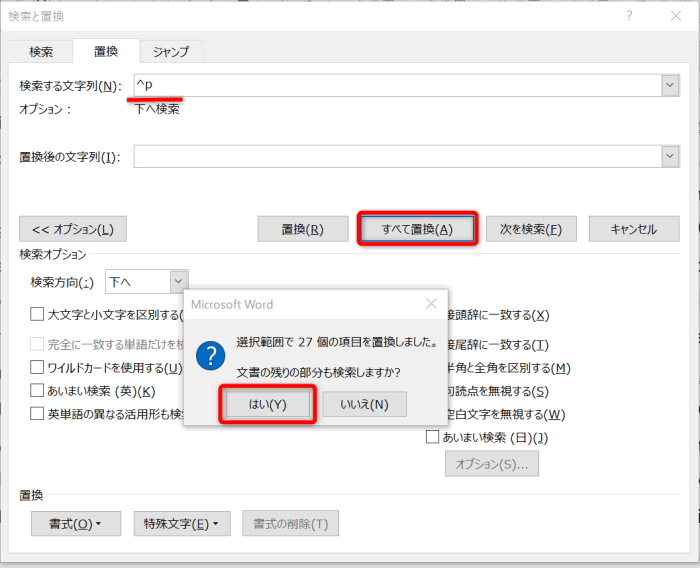
5. [すべて置換]をクリック。すぐに削除が完了し、「選択範囲で○○個の項目を置換しました。文章の残りの部分も検索しますか」と表示されるので、[はい] ⇒ [閉じる]。
これで、改行がすべて削除される。
改行がすべて削除されると、翻訳した後で原文と翻訳結果との確認作業が難しくなるので、原文と翻訳結果の位置関係を確認するという目的で、お好きな位置で改行します。
文字列をざっと見渡し、おかしな部分がないか簡単にチェックする。ここで、新たにハイフネーションが見つかることもある。文章をいくつかの段落に分けると、後で内容の確認時に便利なので、適当なところで段落を入れる。
以上で翻訳原稿の作成完了です。
別の改行マークの場合
Wordに貼り付けたときに表示される改行マークが上の図と異なり、下向きの矢印になるケースがありました。この場合、上の手順で、「段落記号」ではなく、「任意指定の行区切り」を選びます。

DeepL で全文翻訳する
次に、DeepLで日本語に翻訳します。
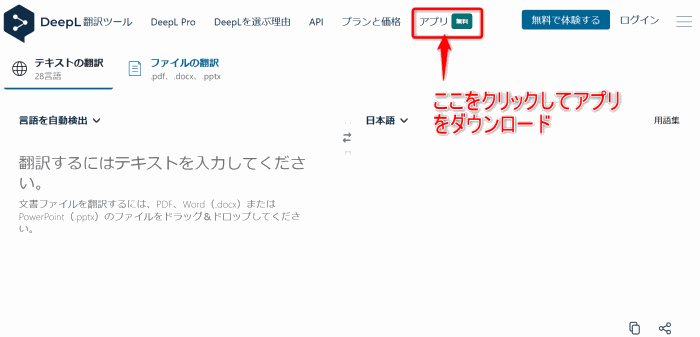
最初に、「DeepL」のサイトから「アプリ 無料」をクリックして、アプリをダウンロードし、インストールします。
これで、5000字までなら無料でDeepLを使えます。翻訳したい外国語を選択した状態で、[Ctrl]+[C]+[C] で翻訳がスタートします。アプリの起動もテキストを貼り付ける必要もありません。
今回は、数百万字の翻訳なので、DeepLと契約する必要があります。契約はDeepLの画面から行ってください。契約すると翻訳文字数制限がなくなり、超巨大な外国語文献でも翻訳可能になります。
契約はいくつかのコースがありますが、おすすめは、Ultimateコース(月額5000円)で契約し、すぐにキャンセルするという方法です。契約解除は簡単にできるので心配不要です。この方法で、テキストの翻訳:無制限、文書ファイルの丸ごと翻訳100ファイル、という条件でDeepLを無料で1ヶ月間使うことができます。契約を解除しても契約日から1ヶ月間は無料で使うことができます。
そもそも、巨大な文献を丸ごと翻訳するというケースは滅多にないと思います。翻訳したいファイルを集めておき、まとめて処理すれば、すべて無料でできます。
Wordに貼り付けた原稿が数百ページになっても、原稿を全選択して、 [Ctrl]+[C]+[C] とするだけで翻訳が完了するのですから、とても楽です。
DeepLは文章全体が長いほど正しい訳に近づくような印象を受けます。ただし、もっともらしい偽の翻訳も時々するので、固有名詞がでてきたら要注意です。原文でチェックした方がよいでしょう。
DeepLで翻訳できるのは外国語だけではない!
翻訳と聞くと、外国語から日本語への翻訳を思い浮かべると思います。DeepLは多くの言語に対応しているため、DeepLで翻訳できない言語はほとんどないと言えます。
ところで、大きな墓地を訪ねたとき、巨大な顕彰碑を見かけることがあります。そこには、小さな文字でたくさん書かれているのですが、読めません。漢字だけで書かれているからです。これをDeepLを使って現代日本語に翻訳できます。
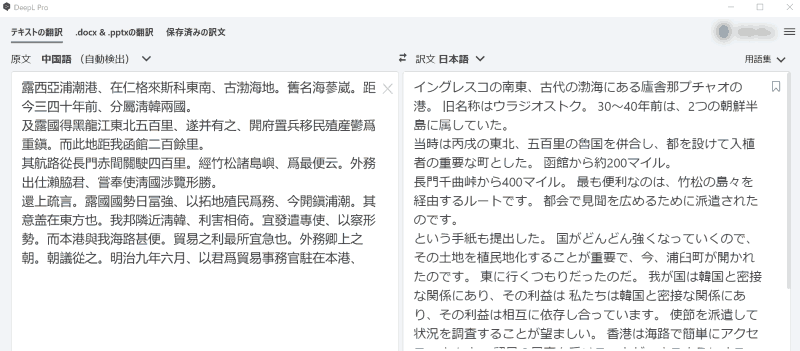
DeepLは、顕彰碑に書かれている文字列を中国語として認識しています。ちなみに、日本だけが古代中国の漢字の読みを現代まで伝えている世界で唯一の国なので、日本人なら読めても中国人には読めないだろうと思われます。現代中国人が難しくて忌み嫌う中国の古典を日本では漢文として高校で学んでいます。
昔の漢文調の日本語を現代日本語に翻訳する。DeepLではこんな使い方もできます。管理人としては、ロシア語の翻訳がDeepLでできるということがうれしいと感じます。
DeepLはとても優れた翻訳をしますが、その翻訳結果が正しいわけではありません。あまり当てにしない方がよいでしょう。DeepL機械語翻訳の「思い込み翻訳」や「こんな文節なかったことにしよう翻訳」、「こんな翻訳どこから出てきたんだ!翻訳」など、かなり悩ましい翻訳もありますが、しかし、Google翻訳よりも100倍正確です(www)。
しかしながら、今回の記事のテーマである数百ページの外国語書籍を読む、という目的はDeepLで達成できます。このような作業をすると、長大な文献の記述の中から特定の記述の箇所を容易に見つけ出すことが可能です。
特定箇所が絞り込まれた後は、その部分の翻訳精度をあげる作業に入ります。詰まるところ、機械語翻訳に頼らず自分で翻訳するということです。
結局は、その方が速く正確に翻訳できます。

