
ふと、「冷やし中華」という文字を見たとき、なぜ送り仮名の「や」が必要なのだろうか、という素朴な疑問が沸きました。「冷し中華」で良いのでは?
同じような疑問を持った方がYahoo!知恵袋に質問されていました。「「冷やし中華」か「冷し中華」か?」と。その回答として、快仁21面相さんが素敵な答えを書いています。詳しくは、リンク先で確認して下さい。「ひやす」は「冷える」に合わせて「冷やす」としているそうです。
原則としては、「冷し中華」で良いのですが、たとえば、「さまし中華」と書きたい場合、「冷し中華」では、「ひやし」と読み、「さまし」とは読みません。このように、「冷」にはいくつもの読みがあるため、送り仮名を増やしているようです。
ATOKでは、「冷し」という候補は表示されず、「冷やし」のみ選択可能です。これが本則であると学習しているのでしょう。MS-IMEでは、「冷やし」と「冷し」の両方が表示されます。
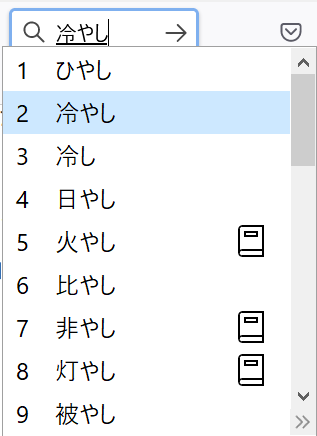
なるほど、と納得した管理人ですが、「いや待てよ! この説明では納得できない事例があるはず」と思いました。
思い出せないのですが、一つの単語が二つの読み方ができる。そして、その意味・ニュアンスが異なる、という事例があったと思うのですが、思い出せません。
ところで、「冷かし中華」って食べたことがありますか? 管理人は、これを「冷やし中華」と読んでしまいます。たぶん、同じように読んでしまう人もいると思います。その原因は外国語学習の後遺症なのかも知れません。助詞を飛ばして読んでしまう。外国語では「冷○し」の「○」の部分が変化しない。名詞と前置詞だからです。日本語の「送り仮名」など外国人には理解不能でしょう。そして、この送り仮名が「や」 ⇒ 「か」に変わっただけで全く別の意味に変化する。
外国人にとって、日本語の送り仮名のルールは難解だと感じます。しかし、日本人なら、当たり前のように使いこなします。学校で勉強したという記憶がなくても、どこかで学習しているのでしょうね。
助詞はやはりとても難しいと感じます。某国の工作員が日本人になりすましているのではないか、と感じたときは、この送り仮名を踏み絵に使えそうです。
日本語の漢字の読みは、日本古来からの和音の他に中国伝来の呉の時代の読み方・呉音と漢音が併存して使われているなど、中国の言語の専門家でなければ分からない中国古典の読みが使われています。その読みに、「送り仮名」が付くため、とても複雑なものになっています。
日本語が上手な外国人はたくさんいるようですが、「冷やし中華」の「や」がなぜ必要なのかを説明できる人はほとんどいないでしょう。日本人でも知らないことです。
送り仮名はとても複雑なのに、日本人は複雑だと感じることはありません。
チャンクって何だ?
日本語はとても難しい言語だと思います。優しい日本人は、外国人が日本語を少しでも話すと「日本語がお上手」と言います。しかし、日本人と同じレベルで日本語を話せる外国人は見たことがありません。何年日本にいても、ハーバード大学出でも、日本人が話すレベルの日本語を習得できないようです。
なぜなのか考えていたら、チャンクが影響しているのではないかと思いつきました。話題のChatGPTは、文章をトークンと言われるチャンクに分けて意味を推測しています。
チャンクとは、ひとまとまりの文字列です。英語圏の人間の頭の中は、聞き取った言葉をチャンクに分解して、意味を理解しようとします。
ところが、日本語には、外国人にとって信じられない「助詞」が存在します。「私は」と「私が」では、その後に続く動詞の使い方が変化します。当然、意味が変化する場合もあります。
英語なら、動詞の後に付く前置詞で意味が変化する場合もありますが、日本語のように主語(名詞)に続く助詞でその後に続く意味が大きく変化するという構造にはなっていません。
英語圏の人間が、日本人のように日本語を話せない理由の一つが、このやっかいな助詞の使い方です。
彼らの頭の中には、常に「チャンク」で文字列を括ろう、という意識が働いていると思います。
そこで、すばらしい日本語を生成するChatGPTのチャンクの構造に興味が沸きます。関心がある方は、ChatGPTに「チャンクで表示して」と命じると、ChatGPTが日本語をどのようなチャンクに分けて理解しているのかが分かります。
ChatGPTにチャンク分けを聞いてみる
上で書いた「優しい日本人は、外国人が日本語を少しでも話すと「日本語がお上手」と言います。」という文字列をChatGPTはどのようなチャンクに分けているのでしょうか。ChatGPTに聞いてみます。
以下はChatGPTが日本語の文章を理解するのに使っている可能性があるチャンク分けの例です:
「日本語は」「とても難しい」「言語だと」「思います。」「優しい日本人は、」「外国人が」「日本語を」「少しでも」「話すと」「「日本語がお上手」と「言います。」
管理人は、「日本語」「は」「とても難しい」「言語だ」「と」「思います。」と分けるのではないかと推測したのですが、違いました。「名詞+助詞」を一つのチャンクとして扱っているようです。なるほど、AIならではのやり方ですね。「名詞+全ての助詞」というデータベースを持っているので、それを参照し、「名詞+助詞(日本語は)」に続く文例チャンクを参照し、推測しているようです。結局これが翻訳にも使われます。
AIにとって、名詞+助詞で文字列を把握し、データベースから次に来るチャンクを推測することなど簡単なこと。だから、ChatGPTは助詞の使い方を間違えないのです。これが、他の機械語翻訳との大きな違いでしょう。Google翻訳など、助詞の翻訳が全くできていないため、意味不明な翻訳をします。
管理人が「チャンク」に着目したのは、「チャンクで覚える英語表現」など英語学習で「チャンク」という言葉をよく目にしたからです。そして、ChatGPTもチャンクを導入して推測に使っていることを知りました。
バイリンガルアナウンサーはチャンクで理解しているのでは?
バイリンガルなアナウンサーはチャンクで理解しているのではないか、という仮説を立てました。
アナウンサーの誤読が話題になりますが、その大半は「漢字の誤読」です。助詞の言い間違いという話しは、ネットで調べても出てきません。
バイリンガルのアナウンサーといっても、日本生まれで日本育ちで海外滞在はせいぜい1年程度なのに2カ国語以上を言語を話せるアナウンサーが多いのに驚きました。逆に、帰国子女がアナウンサーになっている例が少ないことに驚きます。
アナウンサーの漢字の誤読は、読み方を学習すればよいだけのこと。優秀なバイリンガルアナウンサーにとってそれほどハードルが高くはないでしょう。
むしろ、帰国子女がバイリンガルアナウンサーになっていないのが気になります。もしかして、助詞を間違えるから? 助詞を間違えるアナウンサーは放送局として怖くて使えません。ほぼすべての人が間違いに気づくからです。これに対し、誤読は、気づかない場合も多いように思います。
帰国子女がアナウンサーにならない理由は何なのでしょうか。外国語もできて、会社としても採用したい人材なのではないでしょうか。
もしかしたら、チャンクで把握するような頭の構造になっているせいかも。人間はAIのようなことはできません。チャンクで理解しようとすると、助詞の使い方という難関に直面します。人間は全ての助詞の使い方データベースを持っていません。「名詞+助詞」ではなく、「名詞」+「助詞」になるため、どうしても助詞の使い方の経験値がものを言います。海外経験が長ければ長いほど、日本語の習得が難しくなのでしょう。日常生活では何の支障もないのですが、話すことが仕事という職種には向いていないのかも知れません。
アナウンサーを例に取り上げましたが、現実には、日本人の日本語はめちゃくちゃです。Yahoo知恵袋の質問など、管理人には理解できない文章をよく見かけます。外国人ではなく、日本人がいい加減に書くとき特有の言い回し、というか、話し言葉の延長で書かれた文章。対面だから分かる言葉も、文章にすると意味不明なものになる場合があります。私とあなたは理解できるのに、どうして他の人は理解できないの? という世界です。
「優しい日本人」は、こんな質問にも答えています。意味不明なのにどうして回答できるのかが不思議なのですが、回答する方もそれなりの目的でやっているのでしょう。
「優しい日本人」は、外国人から見たら奇妙な存在かも。やはり、質問の趣旨を確認するのが質問者のためにもなるように思います。デタラメ日本語に回答する人がいると質問者のためにもなりません。それは、「優しい日本人」とはかけ離れた行為かも。

